Now I just check stack overflow if there are comments on my past interactions
or, when there are upvotes or downvotes, I go to the answer to see if there
is any improvement I can do on it. I don't like SO as I did in the past
also because there are a sizeable number of jerks around, and the company is
not really doing much about it.
TL;DR:
I wrote a technically correct answer. A ignorant poweruser defaced it. I asked what to do in meta and I
was told to restore it. The same poweruser deleted it. Flagged for moderators help. An ignorant moderator
came, undeleted and then redeleted it. End of part 1. After a few years I checked in again on the issue
and instead of making someting constructive I was attacked again. Meta discussion removed. Game Over.
Many moderators simply watched this happening.
As an example (not the only one, but the most prominent that happened to me personally) I was bullied
by ignorants powerusers and moderators that first defaced, then downvoted, then deleted twice my
correct answer and nothing happened when reporting the incident on meta (except more bullying).
The post was about a crash, and the main problem was a common mistake made by many C++ newbies
on thinking that sizeof(array) does return the number of elements instead of
the number of "bytes". So far so good and nothing happened.
What triggered the whole problem was however that I wrote "number of characters" instead of number
of bytes, with the explicit description of why: sizeof(x) returns the number of "bytes",
but not the "bytes" that most programmers would be thinking to, but the "byte" definition in the C++
standard, that can have MORE than 8 bits.
Yes. You read it right. A "byte" can have more than 8 bit (the for the meaning of "byte" word used
in the C++ standard document). More specifically a "byte" does have
CHAR_BIT bits and
that number is at least 8. The exact phrasing in one of the revisions is (emphasis mine):
The fundamental storage unit in the C++ memory model is the byte. A byte is at least large enough to contain
any member of the basic execution character set (5.3) and the eight-bit code units of the Unicode UTF-8
encoding form and is composed of a contiguous sequence of bits, the number of which is implementation-
defined. The least significant bit is called the low-order bit; the most significant bit is called the high-order
bit. The memory available to a C++ program consists of one or more sequences of contiguous bytes. Every
byte has a unique address.
This is for example the reason for which
sizeof(char) is always 1 but
char values may have
more than 8 bits. Anyone that writes
sizeof(char) is simply showing ignorance about this fact
(not a crime, of course). Actually in my experience very few programmers do actually know that
char can
have 16 (or even more) bits and that
sizeof(char) is still 1 anyway.
I first bumped into this "oddity" at university when a friend told me he was working on a (then) supercomputer
(a Cray or something similar) that had two modes of compilation... one with 32-bit chars that was the fastest
and one with 8-bit chars (more compact representation of strings).
On that computer (when compiling in 8-bit mode) a char pointer was bigger than other kinds of pointers
because it also stored the part of the 32-bit word to point to (the hardware was unable to access just 8 bit),
the minimum addressable unit (at hardware level) was 32 bit.
I found again one of these "odd" systems when I joined COMELZ (my current employer) in 1999: on the other
end of the computing power, one of the CPUs we use on axis control cards is a Texas Instrument DSP where
CHAR_BIT is 16, as the hardware doesn't provide 8-bit memory access. On one card for example
memory is 16Kb of 16-bits "bytes" (i.e. 16384*16 = 262144 bits in total, the same as 32Kb on an X86 pc).
Another 20+ year passed since then, and still today CHAR_BIT can be more than 8. It's not
a thing of the past. It's not even an extremely uncommon thing... (even if today for sure is not the most
common case: even "small" computers now have quite sophisticated hardware, often implementing a
full POSIX system including file systems, network, multitasking).
When I wrote my answer also adding that the idea that
sizeof(x) returns the size in
8-bit bytes is a common misconception, because a "byte" can have more than 8 bit, the answer was
defaced and the explanation removed with the comment "The misconception is yours. Fixed.", by someone
that now has 300K+ reputation.
Over the years something that became apparent to me is that idiots and other kinds of badly behaving persons
is a "dense" subset in any group. There are idiots among priest, engineers, medicians, rich people,
poor people, white, blacks, straight, gay... any kind of group you may want to classify people in.
Even kids. In my opinion if probably a very young kid (say below 4-5) can still be "fixed" by proper
education, I'm personally not so sure a bad person at 15 can become a good adult... possibly they
can learn how to stay within socially accepted (i.e. legal) limits, but they'll probably never become
really good persons. This is bad and sad, and I'd love to be proved otherwise, but this is my impression.
This also applies to technical merits and titles. There are people with official degrees that know nothing,
super tech "experts" that would never be able to complete any project working alone and also would
just create problems in any group you place them in. There are best selling authors that know nothing
and write books filled of bad ideas and factually wrong "facts". Medicians you should run away from if
you care about your life and health.
I'm not saying they're the majority (they're not), but they do exist. It just happens. Never let a
title lower your guard. Never let popularity lower your guard. Even what a 300K+ user writes on Stack
Overflow can be wrong; they can even be quite vocal to the point of being rude and act as if they
know their shit: that still doesn't necessarily imply they're right. In this case the 300K was wrong.
As I got my answer defaced that way by an high-reputation user (SO reputation, just a number that however
grants special powers on the site like editing other users answers instead of just proposing changes) I
asked in meta and was suggested to just edit the answer back even if of course it was wrong (who replied also
tought I was wrong... like I said not many know what a byte is for C++).
I did as suggested and also tried to fix the prose so that it was clear what I meant (including changing
for example "characters" to char).
Then I got quite a few downvotes in a short span of time (probably the "meta effect") and then the
same poweruser and a couple of others deleted my answer.
I flagged for moderator intervention and voted for undelete. A moderator came, undeleted the answer
and then re-deleted it (the little paranoid in me now thinks it could have been a move so that now
I cannot ask for undelete again). Note also this moderator (also high rep and "worked as NASA") did not
actually know a shit about what a byte is in C++.
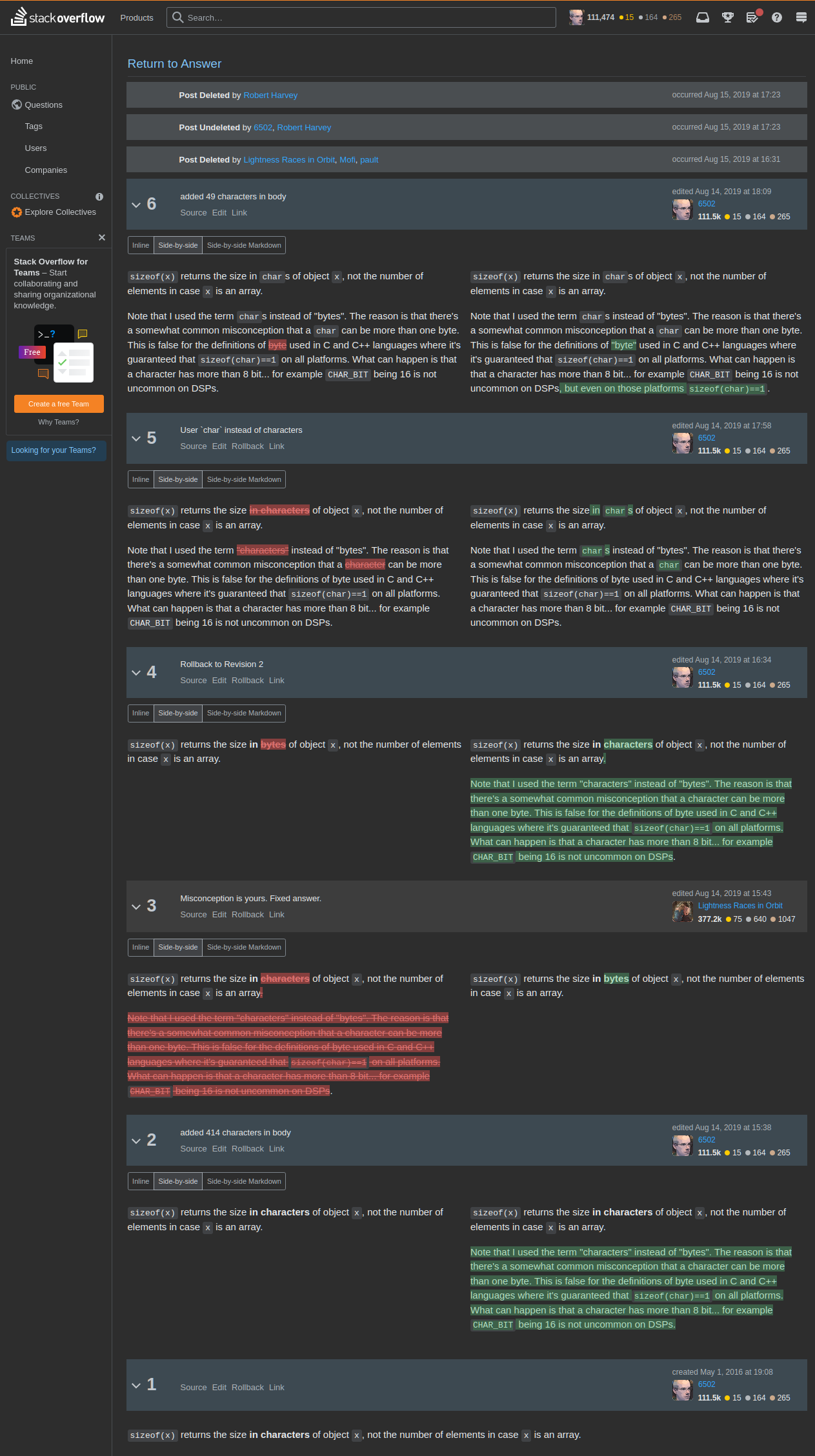
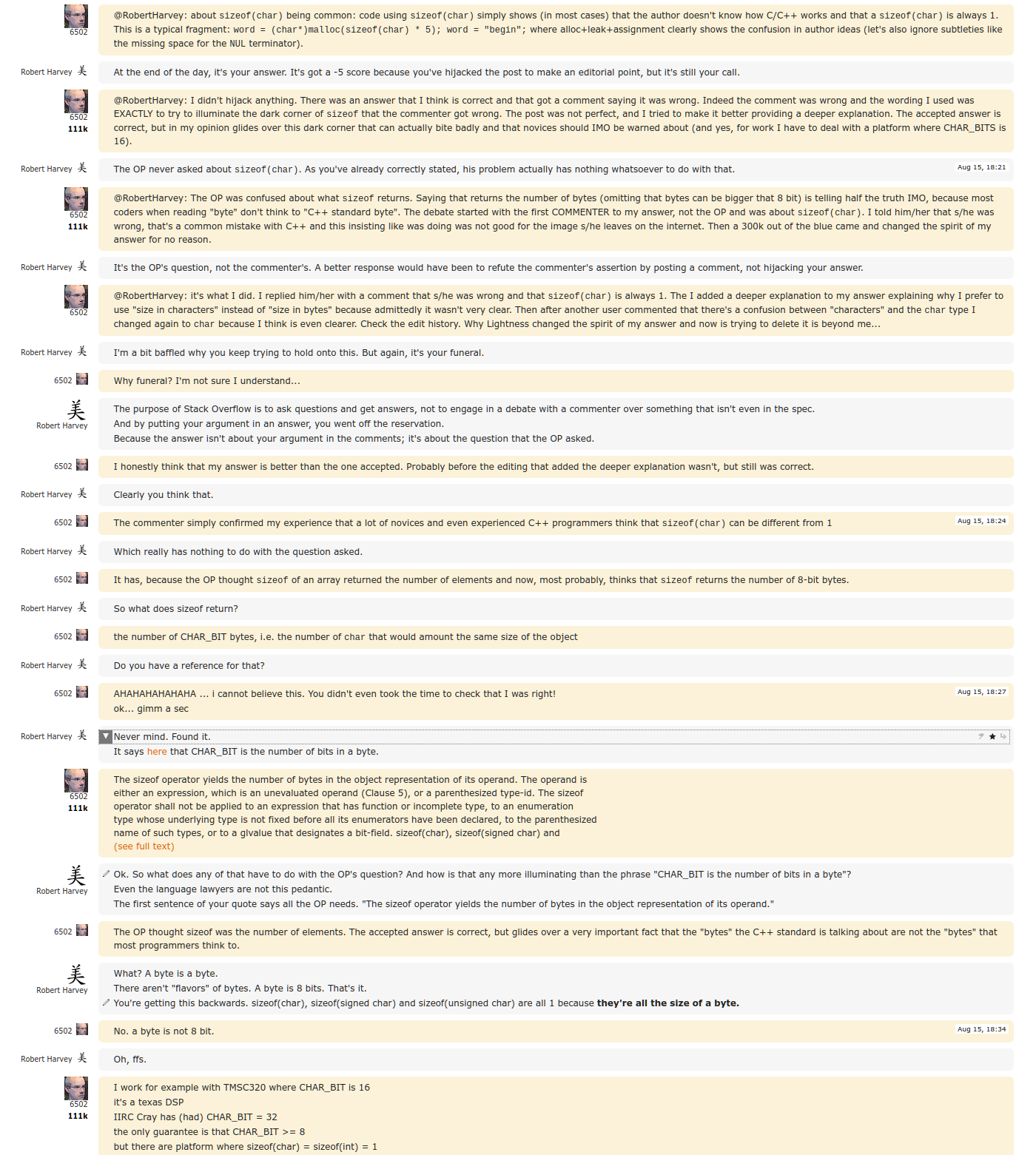
This is a snapshot of what happened... saving as images here as I start to suspect there's no
limit to what could happen to the chat or answer history given this was the behavior of a moderator
on Stack Overflow and those are just bytes on their servers and they can change them at will
any time.
And that's it. I was bullied by an ignorant high-rep. Asked for help and a moderator punched me again
and killed my (innocent and correct) answer forever.
A few days ago when going on Stack Overflow a banner was thrown on my face about a new Code Of Conduct.
I never thought about SO Code Of Conduct so I took the time to read it and (now) includes a section
about abusing of power user tools. So I asked on meta what is the time limit for a report, also making
clear that I don't know what was the CoC before.
Unfortunately still nothing changed over the years. I was attacked because apparently nothing bad
happened to that answer. I was even threatened of false accusations (?) by a new fresh idiot.
Then all the discussion was just removed as non relevant by a nice moderator and the site and its
fake Code Of Conduct is just happy again.
I don't think I'll formally apply for a Code Of Conduct violation... surely everyone involved knows
and many other moderators know. They are the ones that decide what is going to be the outcome.
They clearly don't care about what is technically true and correct, they don't care about what is
correct behavior. I'm not even going to receive excuses for the mistake. That correct answer is not
going to be restored. No one is "above" them, it's their playground and they like to play god there.
I'm just annoying and I should just disappear.
Time is the most precious resource we have (at individual level) and I don't want to waste more
discussing with static dumb ignorants (the ones that are not smart enough to admit when they didn't
know something, learn and improve; intelligent ignorants are instead very valuable people, when they're
also curious they're the best to work with).
I somehow used to have a better idea of what Stack Overflow is, but reality is very very far from
that (at least now).
 I have been born in 1966 in Vigevano and I have always been living
here except for a few nice years during high school
when I was in Intra (on Lago maggiore) and for about one year
when I was living and working in California.
I have been born in 1966 in Vigevano and I have always been living
here except for a few nice years during high school
when I was in Intra (on Lago maggiore) and for about one year
when I was living and working in California.